Figure 1. Replicator block diagram
Perforce Defect Tracking Integration Project
This is the Perforce Defect Tracking Integration (P4DTI) Integrator's Guide. It explains how to extend the P4DTI to work with defect tracking systems that aren't supported by the standard distribution, or adapt the P4DTI to work with a supported defect tracker but in some way that isn't supported.
The intended readership is developers adapting or extending the P4DTI, and project staff.
This manual is not confidential.
The Integration Kit is a copy of the development sources for the P4DTI. The directory layout is summarized in the index to the kit.
I use some words in a precise way to express the importance of an instruction.
I say "must" when the instruction is critical. This means that the integration will fail if the instruction is not followed.
I say "should" when the instruction is essential. This means that integration will be of noticeably lower quality than the supported integrations if the instruction is not followed. However, it won't fail.
I say "may" when the instruction is optional. This means that the integration will not suffer much if you don't follow the instruction.
This section gives an overview of the requirements, architecture and design of the P4DTI, with references to the documents that provide more detail. You must have a good overall understanding of the P4DTI in order to extend or adapt it.
This manual assumes you are familiar with the following subjects:
The jobs subsystem of Perforce, and the relationship between jobs, fixes and changelists [Perforce 2001-06-18a, 10].
How the P4DTI works, from the administrator's point of view. I strongly recommend that you download, install, configure and run one of the supported integrations, following the Perforce Defect Tracking Integration Administrator's Guide [RB 2000-08-10a], so that you know what the administrator has to know and do, where the data is stored, what problems can occur.
How the P4DTI works, from the user's point of view. I strongly recommend that you try out one of the supported integrations, carrying out all the tasks in the Perforce Defect Tracking Integration User's Guide [RB 2000-08-10b], so that you know what it's like to use, and what benefit the users get.
The programming language Python. See the Python web site <http://www.python.org/> for downloads and documentation. If you're new to Python, try the tutorial [van Rossum 2000-10-16], or the book Programming Python [Lutz 1996].
The five most important requirements are these [GDR 2000-05-24, 1-5]:
Defect tracker state is consistent with the state of the product sources.
The defect tracking integration makes the jobs of the developers and managers easier (i.e. make it easier for them to produce a quality product etc.).
It is easy to discover why the product sources are the way they are, and why they have changed, in terms of the customer requirements.
The interface that allows Perforce to be integrated with defect tracking systems is public, documented, and maintained.
The integration provides the ability to ask questions involving both the defect tracking system and the SCM system.
The P4DTI meets requirement 1 and requirement 5 by replicating data between the defect tracker and Perforce (see section 2.3). It meets requirement 2 by making it possible for developers to do their routine defect tracking activity entirely from Perforce (by making the defects available through Perforce's jobs interface). It meets requirement 3 by supplying a user guide [RB 2000-08-10b] that describes a development process in which issues are linked to changes by making fixes in Perforce. It meets requirement 4 by making the project sources and documents available to the public.
See the Perforce Defect Tracking Integration Project Requirements [GDR 2000-05-24] for a full and maintained set of requirements and references to their original sources.
The P4DTI meets these requirements using a replication architecture [RB 2000-08-10c]. A replicator process repeatedly polls two databases (Perforce and the defect tracker) and copies entities from one to the other. This makes and keep them consistent, to meet requirement 1; it makes them available to users of both systems, to meet requirement 2; and it makes them available for queries combining data from both systems, to meet requirement 5.
The replicator replicates four relations:
Issues are replicated from the defect tracker to Perforce (where they appear as jobs). Changes to issues and jobs are replicated in both directions, but the Perforce jobs are considered to be a subsidiary copy of the real data in the defect tracker. This means that when the two databases differ (for example, because they have been changed simultaneously) the defect tracker is considered to be definitive.
Changelist descriptions are replicated from Perforce to the defect tracker.
Fixes (links between issues and changelists) are replicated in both directions.
Filespecs (links between issues and files) are replicated in both directions.
The P4DTI replicates the filespec relation in order to support use cases like "Associate revisions of documents with task" [GDR 2000-05-03, 6.2] and "Check out copies of revisions of documents associated with task" [GDR 2000-05-03, 6.3] and to support defect trackers like DevTrack by TechExcel that provide a revision control interface based on associating documents with an issue. However, because the currently supported defect tracker (Bugzilla) has no such feature, and because alpha and beta testing showed no demand for use cases involving associating documents with tasks, we haven't made any use of this relation (for example, it's not documented in the user's guide). However, it's there if you need it for integrating with your defect tracker.
The replicator is designed to be highly independent of both Perforce and the defect tracker, using public interfaces wherever possible, so that the integration doesn't have to change frequently to keep up with the systems it integrates (requirement 27) and the cost of maintenance is low (requirement 30). It runs as a separate process and uses public protocols to access both databases. It doesn't require any special support from either system (though users benefit if the defect tracker provides an interface to Perforce fixes; (see section 10).
The replicator is written in the interpreted programming language Python, a portable, stable, readable and open programming language (to meet requirement 21, requirement 24, requirement 25, and requirement 26.).
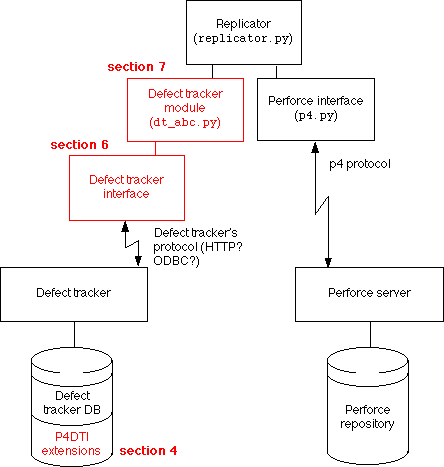
Figure 1 below shows the broad outlines of how the replicator is constructed. Parts in black are shared by the integrations with all defect trackers. The components in red are the components that you must write in order to integrate with your defect tracker.
If you need to modify any other components to integrate with your defect tracker, that's a defect in the integration kit. Please report it (see section 12.1) or make the necessary modifications and submit them as a contribution (see section 12.2).
Figure 1. Replicator block diagram
This section gives an overview of the work required in adapting an existing integration or developing a new integration.
Someone might already have developed the integration or adaption that you plan to work on. Take a look at the P4DTI contributions page <http://www.ravenbrook.com/project/p4dti/contrib/>.
Someone might be currently be working on the integration or adaption that you plan to work on. If so, Perforce support may know about them.
The feature you want may in fact be part of the supported P4DTI product and it is missing from the manuals or the manuals are unclear. If so, Perforce support can tell you. And if the manuals are unclear or missing information, then please submit a defect report (see section 12.1).
The Perforce Defect Tracking Integration Kit is a supported product. If you have trouble adapting the P4DTI or developing an integration after following the instructions in here, contact Perforce support for help.
Ravenbrook Limited may be able to develop or consult on adaptions and extensions to the P4DTI.
You may need to adapt the P4DTI to work with a supported defect tracker but in some way that isn't supported. For example:
In these and many similar cases, make the P4DTI do what you want by writing a "configuration generator" (see section 8.6).
But don't skip straight to that section. At least skim the rest of the manual. You'll need to understand many of the details in order to write a configuration generator, especially how to write translator classes (see section 7.5) and how the configuration works (see section 8).
Follow these steps to integrate Perforce with a new defect tracker:
Choose a name for the integration. This should be the name of the defect tracker, for example "Bugzilla". This name (when converted to lower case) must be used as part of the names of modules making up the integration (see section 7 and section 8).
Decide which of the optional features you are going to support (see section 3.5).
Provide full implementations of these components:
You should develop and apply tests (both automated and manual) of your integration (see section 9).
You should provide a defect tracker interface to the Perforce relations, if possible (see section 10).
You must adapt or extend these components:
The configuration module config.py (see section 8.5).
The Administrator's Guide (see section 11);
The User's Guide (see section 11);
All other components are designed to be portable between defect trackers. If your integration cannot be made to work without changing the portable components, then there is a defect in the P4DTI Integration Kit. Please report this (see section 12.1).
Once all the work outlined above is completed and tested to your satisfaction, you should make your work available to the community so that others can benefit from your efforts (see section 12.2).
I estimate that at least 10 weeks of effort are required to develop, test, document and release a new integration [GDR 2000-05-30]
The features in the following list are optional. You should
implement as many as possible. Use the supports method of your defect tracker
interface to specify to the P4DTI the features that you support.
Replication of fixes between Perforce and the defect tracker, and replication of changeslists from Perforce to the defect tracker.
Replication of file specifications between Perforce and the defect tracker.
Creation of new issues in the defect tracker based on jobs in Perforce (during migration).
Creation of new issues in the defect tracker based on jobs in Perforce (during normal operation of the P4DTI).
Creation of new users in the defect tracker based on users in Perforce.
You must extend the database schema by adding new fields to the issue relation (see section 4.1), and adding three new relations: the changelist relation (see section 4.2), the fixes relation (see section 4.3), and the filespecs relation (see section 4.4). You should add another relation to the database, to store the replicator state and configuration (see section 4.5). These schema extensions must be documented so that users of your integration can implement database queries and reports that use this data, to meet requirement 5.
These relations should be stored in separate tables if possible, to most easily support queries and reporting using standard database tools. However, some defect trackers do not support this.
Example. TeamTrack release 4.5 doesn't support the addition of tables to its database schema, so the TeamTrack schema extensions squashed these relations into a single table, using a type field to distinguish them [GDR 2000-09-04, 2.1].
The design must support multiple replicators replicating from a single defect tracker, and support a single replicator replicating to multiple Perforce servers from one defect tracker, in order to meet requirement 96. To support this, each relation includes a replicator identifier which identifies the replicator which is handling replication for that record, and a Perforce server identifier, which identifies the Perforce server that the record is replicated to.
Examples. The TeamTrack database schema extensions [GDR 2000-09-04] and the Bugzilla database schema extensions [NB 2000-11-14b].
The issue relation must be extended with these fields:
| Field contents | Field type |
|---|---|
| Replicator identifier of the replicator that is in charge of replicating this issue, or the empty string or NULL if the issue is not replicated. | char(32) |
| Server identifier of the Perforce server to which this issue is replicated, or the empty string or NULL if the issue is not replicated. | char(32) |
| Name of Perforce job to which this issue is replicated, or the empty string or NULL if the issue is not replicated. | char(1024) (or varchar(1024) since most jobnames are
short). |
You may add these fields to the defect tracker's issue table, or you may store them in a separate table and use the issue key to relate the two tables.
Examples. The TeamTrack integration added the new fields to the existing
TS_CASEStable [GDR 2000-09-04, 3.1]. The Bugzilla integration creates a tablep4dti_bugscontaining the new fields and associates them with thebugstable using thebug_idfield [NB 2000-11-14b].
(Changelists belong to the fixes feature.)
The changelist relation has these fields:
| Field contents | Field type |
|---|---|
| Replicator identifier. | char(32) |
| Perforce server identifier. | char(32) |
| Change number. | int |
| User who created the change. | A foreign key reference to the defect tracker's user relation giving the user who created or submitted the change. |
| Change status. | An enumeration with two values: pending or submitted. |
| Date the change was last modified. | A date and time. |
| Change description. | Text, unlimited in length. |
| Client from which the change was submitted. | char(1024) (or varchar(1024) since most client names are
short). |
The combination of (change number, Perforce server identifier) is the primary key for this relation: there can only be one change with a particular number on a Perforce server.
(Fixes belong to the fixes feature.)
The fixes relation has these fields:
| Field contents | Field type |
|---|---|
| Replicator identifier. | char(32) |
| Perforce server identifier. | char(32) |
| Issue. | A foreign key reference to the defect tracker's issue relation, giving the issue which is fixed by the change. |
| Change number | int |
| Date the fix was last modified. | A date and time. |
| User who created the fix. | A foreign key reference to the defect tracker's user relation, giving the user who last modified the fix. |
| Status the job was/will be fixed to. | char(1024) (or varchar(1024) since most job statuses are
short). |
| Client from which the fix was made. | char(1024) (or varchar(1024) since most client names are
short). |
The combination of (issue, change number, Perforce server identifier) is the primary key for this relation: there can only be one fix between a change and an issue on a Perforce server.
(Filespecs belong to the filespecs feature.)
The associated filespecs relation has these fields:
| Field contents | Field type |
|---|---|
| Replicator identifier. | char(32) |
| Perforce server identifier. | char(32) |
| Issue. | A foreign key reference to the defect tracker's issue relation, giving the issue which is fixed by the change. |
| Filespec. | Text, unlimited in length. |
By design, the replicator has no internal state. This is to make the replicator robust against losing a network connection, or the machine it's running on crashing in the middle of a replication: when the network comes back up or it starts again, it tries the replication again [GDR 2000-09-13, 2.9]. This design principle helps to meet requirement 1 (consistency between databases).
This means that if you need to store information, such as a record of which changes have been replicated (see section 4.6) you must store it in the defect tracker's database.
The replicator also needs to pass information to the defect tracker,
to support an interface from the defect tracker to Perforce (see section 10). There are three configuration
parameters which should be communicated to the defect tracker by storing
them in a configuration table: changelist_url, job_url, and p4_server_description.
The replicator works by repeatedly polling the databases, so you must provide a way to tell it which issues have changed since the last time it polled. Here are some strategies:
If the defect tracker has a changes table which records the history of changes to issues, then store a record number in the replicator state that gives the last record in the changes table that has been replicated.
Example. The TeamTrack integration used this approach [GDR 2000-09-04, 3.5].
If the defect tracker has a last modified date field in the issue table, store the value of this field at the point when the replicator was last replicated. Then you can fetch the changed issues by looking for issues whose last modified date is greater than the last replicated date. This is likely to be less efficient than solution 1.
Modify the defect tracker so that it supports solution 1 or 2.
If all else fails, store a "shadow" table of issues, containing copies of the issue records as they were when last modified. Then you can find changed issues by finding differing corresponding records. This is likely to be very inefficient.
The replicator needs to distinguish the changes it made from changes made by other users of the defect tracker. Otherwise it attempts to replicate its own changes back to Perforce. This won't actually end up in an infinite loop of replication, since when it replicates back it discovers that there are no changes to be made, and so not actually do anything. However, this double replication gives twice the opportunity for conflicts, and hence annoying e-mail messages for the users of the P4DTI (see Ravenbrook issue job000016).
Here are some strategies:
Suppose that the defect tracker has separate concepts of "logged in user" and "user who is making the change". In this case, make a special user to represent the replicator and have the replicator log in as that user. The replicator's changes show up with logged in user being the replicator user; all other changes need to be replicated.
Example. The TeamTrack integration used this approach [GDR 2000-09-04, 5].
Store a table listing the changes that were made by the replicator. Any other changes need to be replicated.
If the defect tracker has a last modified date field in the issue table, store the value of this field at the point when the replicator was last replicated. Then an issue has been changed by someone else if its last modified date differs from the last replicated date.
The replicator replicates user fields in issues, changelists and fixes (for example, the owner of an issue or the user who submitted a changelist) by applying a user translation function (see section 7.5.4). When a defect tracker user has no licence in Perforce, the translation function can simply use that user's defect tracker login name, since Perforce doesn't validate user fields in jobs. But if a Perforce user has no licence in the defect tracker, the translator needs to do something with them. For issues your defect tracker interface should simply refuse to replicate when a Perforce user has no licence in the defect tracker. But you should be less strict when replicating fixes and changelists: while it is a sensible policy (and required by some defect tracker vendors) to require the current owner of a job in Perforce to have a licence, it is not sensible to require every user in Perforce who ever submitted a changelist to have a licence in the defect tracker.
Example. The TeamTrack integration mapped unknown users in changelists and fixes to the special TeamTrack user 0 (representing "no user"). When there's an unknown user in an issue, the integration rejects the attempt to replicate it by raising an error.
This section covers coding conventions followed in the P4DTI. You should follow these conventions in your adaptions and extensions. They make your code more reliable and easier to debug, and make it easier for users to diagnose problems and fix them. If you contribute your code for inclusion in the P4DTI (see section 12.2) then it is easier for us to integrate your contribution.
Example. Look at the Bugzilla module,
dt_bugzilla.pyfor uses of all conventions and features covered in this section.
The message.py module defines a class of
messages. You must use this class when writing messages to the
replicator's log (see section 5.3). You
should use this class when raising errors (see section 5.4).
You create a message like this:
import message id = 123 text = "Constructed a test message." priority = message.DEBUG product = "Test" msg = message.message(id, text, priority, product)
The four arguments to the constructor are as follows:
idA message identifier (an integer). This is unique among all messages generated by the product.
textThe text of the message (a string).
priorityThe level of importance of the message. This must be one of the constants in the following table:
message.CRIT |
A critical error: the replicator stops immediately. Use this
priority for errors in configuration discovered by your
configuration generator or by the __init__ and init
methods of your defect tracker interface. |
message.ERR |
An error. The replicator can't complete some operation. Use this priority for errors discovered during replication, such as untranslatable fields or permission failures. |
message.WARNING |
A warning. The replicator can continue, but the administrator may want to take some action.
|
message.NOTICE |
A significant but expected condition.
|
message.INFO |
For information only. |
message.DEBUG |
Unlikely to be useful except for debugging. |
product The name of software product which generated the message. For
the supported P4DTI, this must be "P4DTI".
You can format a message as text by converting the message object to a string:
>>> str(msg)
"(Test-123X) Constructed a test message."
Note that a check digit has been appended to the message identifier. (The check digit uses a mod-11 algorithm similar to that used in ISBNs [ISO 2108], so the check digit can be 0-9 or X.) The idea of the check digit is so that Perforce support can ask users for the message identifier of the error that they are reporting. The check digit makes it very likely that if the error is misreported or misheard the mistake is detected.
You can wrap a message to some number of columns by calling its
wrap method:
>>> print msg.wrap(25)
(Test-123X) Constructed
a test message.
You may create each message when you need it, but you should use a message catalog. A catalog helps you keep message identifiers distinct and internationalizes your code.
A message catalog is a dictionary that maps message identifier to a tuple of two elements: the message priority, and a format string that can be used to build the message text. For example:
# Test catalog in English
test_en_catalog = {
123: (message.DEBUG, "Constructed a test message."),
124: (message.CRIT, "Couldn't connect to defect tracker on host '%s'."),
125: (message.ERR, "User '%s' has no permission to edit issue '%s'."),
126: (message.INFO, "Replicated issue %d."),
# ...
}
Note that a message catalog must not have an entry for message id 0. That's reserved for errors from the catalog implementation.
Once you have a message catalog for a product, you should build a message factory that dispenses messages from that catalog, like this:
import message product = "Test" factory = message.catalog_factory(test_en_catalog, product)
Now you can construct a message by calling the factory's new method and passing the message identifier,
and the arguments for the format string:
msg1 = factory.new(124, 'dt.ravenbrook.com')
msg2 = factory.new(125, ('gdr', 'BUG00123'))
See the catalog.py module for the P4DTI catalog and
message factory.
The P4DTI
logs its progress and errors by creating messages (see section 5.1) and sending them to a "logger":
that is, an instance of the logger class defined by the logger.py module.
The logger module defines classes for logging to files, to standard
output, and to the system log on Unix. The multi_logger class directs a single message to
several loggers. Each logger class takes a priority argument on
instantiation: only messages with this priority, or a higher priority,
appear in the log.
You should log as many debugging messages as you like (by default
the log_level configuration parameter is message.INFO so these messages won't appear). You
should log informational messages sparingly, and only when you actually
make a change in a database. You should not log error messages, but
should raise them as exceptions instead (see section 5.4); the replicator logs them for you
when it catches them.
To add a message to a log, create a message object (see section 5.1) and pass it to the logger's
log message:
import logger
# Log messages of priority INFO and higher to test.log:
logger_object = logger.file_logger("test.log", message.INFO)
msg = factory.new(126, issue_id)
logger_object.log(msg)
The configuration generator (see section 8)
must construct a logger object for use by the replicator. The same
logger object should be used by the defect tracker module (see section 7) as well, so that all messages are
collected in the same place. You must allow the P4DTI administrator to control the
volume of log messages by setting the log_level configuration parameter.
In the P4DTI, errors are indicated by raising a Python exception, not by returning an exceptional value.
Raise an error using a string as the exception object, and a message object (see section 5.1) as the message. For example:
error = "Example error" # ... raise error, factory.new(124, 'dt.ravenbrook.com')
It doesn't make any difference what priority you give to the
message, but it is conventional to use message.CRIT when the replicator stops (for
example, configuration errors), and message.ERR when the replicator continues (for
example, untranslatable fields or permission failures).
You should include in each file of source code:
The author.
An introduction explaining what the file is intended to achieve: for example, which requirements does it help to meet?
A references section listing the sources you've used in preparing the code and which other people need to read in order to understand it. You should certainly refer to the appropriate sections in this manual.
A history section listing the changes made to the code, with the date and the person who changed it.
A statement of copyright.
A licence giving people permission to copy the file under certain conditions (or denying them permission if that's what you intend).
Example. The
logger.pymodule displays all these features.
If you make a change to the P4DTI that you want to contribute to the project (see section 12.2), you should follow the rules in this section. The reason for this is that if we accept your contribution, we'll merge it into our product sources. It must be possible to carry out this merge reliably and without introducing errors. That means being able to consider each change separately, evaluate it and make a decision about how to merge it.
To enable us to do so, follow the following rules:
Don't delete stuff. Comment it out or skip it.
Don't fiddle with the formatting of code or comments. It creates bogus conflicts that create extra work when merging.
Add comments explaining why a change was made. Sign the comments with your name and the date. Explain why you had to make the change. Refer to defect reports when fixing them.
You'll need a way for Python to read and write defect tracking records. If the defect tracker has an API of some sort, you'll need to use that; if not, you'll have to read and write the database directly, using one of the Python database interfaces. Your defect tracker interface needs to support these kinds of operations:
Get an issue record.
Update an issue record.
Create a new issue record (if you support the migrate_issues or new_issues features).
Get all the issues needing replication.
Get all the fixes for an issue (if you support the fixes feature).
Add/update/delete a fix (if you support the fixes feature).
Create a table.
Add a field to a table.
Get a list of the fields that make up the issue relation, together with the field types, lengths, legal values, etc.
Get a list of users, with names, userids, e-mail addresses.
Add a new user (if you support the new_users feature).
I can't give you a complete or precise list of operations here; you'll have to see what's required as you implement your schema extensions (see section 4) and defect tracker module (see section 7).
Example. The TeamTrack integration used the TeamShare API to connect to the defect tracker, because the API provides methods that apply TeamTrack's privilege system and database validation. The integration used a Python extension module that provided an interface to the parts of the TeamShare API that it needed (only a small part of the whole API, as it happened). See the design of the interface to Teamtrack [GDR 2000-08-08].
Example. Bugzilla has no API: you have to understand the Bugzilla database schema [NB 2000-11-14a] and connect directly to the MySQL database. The Bugzilla integration uses a wrapper module that encapsulates the direct database operations as defect tracker oriented functions like
update_bug. Seebugzilla.pyand its design [NB 2000-11-14c].
You must create a module called dt_defect_tracker.py (where defect_tracker is the lower-case form of
the name your chose for your defect tracker (see section 3)) that implements these classes:
The defect tracker interface itself: a subclass of dt_interface.defect_tracker (see section 7.1).
Defect tracker issue: a subclass of dt_interface.defect_tracker_issue (see section 7.2).
If you support the fixes feature,
defect tracker fix: a subclass of dt_interface.defect_tracker_fix (see section 7.3).
If you support the filespecs
feature, defect tracker filespec: a subclass of dt_interface.defect_tracker_filespec (see section 7.4).
A translator between dates in the defect tracker and Perforce:
a subclass of translator.translator (see
section 7.5.1).
A translator between multi-line text fields in the defect
tracker and Perforce: a subclass of translator.translator (see section 7.5.3).
A translator between users in the defect tracker and Perforce:
a subclass of translator.user_translator
(see section 7.5.4).
Any other translator classes that are needed to translate fields in the issue relation (see section 7.5).
Example. The Bugzilla module,
dt_bugzilla.py.
dt_interface.defect_tracker class A subclass of dt_interface.defect_tracker implements the
replicator's interface to a defect tracker.
Example. The
dt_bugzilla.pymodule defines a classdt_bugzilla.
A subclass of dt_interface.defect_tracker must define the
following methods:
__init__(self, config) This is called when the defect tracker object is created. The config argument is an object whose attributes are
the configuration parameters for the defect tracker. See section 8 for the details of how configuration
parameters end up in this object.
This method should check that all configuration parameters are
supplied and have valid values. Use the methods in check_config.py
for basic checks.
The required parameters should certainly include changelist_url, job_url, p4_server_description, rid, sid, and start_date, but may include others, either
supplied by the P4DTI administrator in config.py or generated by the configuration
generator.
add_replicator_user(self) (The add_replicator_user method
belongs to the new_users feature.)
This method is called during migration from Perforce to request
that the distinguished replicator user be added to the defect tracker.
The e-mail address of this user is defined by the replicator_address configuration
parameter).
If there is already a user in the defect tracker with this e-mail address, then do nothing. Return the userid of that user.
If there is no such user, then if possible add a user to the
defect tracker who will in future be mapped to the replicator's
Perforce user (p4_user) by your user translator (section 7.5.4). Return the userid of the
new user.
If it's not possible to add such a user, return None.
This method is optional. You need not provide it if you don't support migration of users from Perforce.
add_user(self, p4_user, email, fullname) (The add_user method belongs to the new_users feature.)
This method is called during migration from Perforce to request that
a user be added to the defect tracker. The p4_user argument is the userid in Perforce; the
email argument is the user's e-mail address,
and the fullname argument is the user's full
name.
If there is already a user in the defect tracker who is mapped to this Perforce user by your user translator (section 7.5.4), then do nothing. Return the userid of that user.
If there is no such user, then if possible add a user to the defect tracker who will in future be mapped to the this Perforce user by your user translator (section 7.5.4). Return the userid of the new user.
If it's not possible to add such a user, return None.
This method is optional. You need not provide it if you don't support migration of users from Perforce.
all_issues(self) Return a cursor (see section 7.6) that
fetches all defect tracking issues that either (a) are replicated by this
replicator or (b) are not replicated and have been modified since the
starting point for replication (that is, the date given by the P4DTI
administrator in the start_date parameter).
Include in the cursor:
Issues replicated by this replicator (that is, the replicator
identifier for those issues matches the rid configuration parameter);
Issues not replicated by any replicator (that is, the replicator identifier for those issues is blank) and changed since the start date.
Omit from the cursor:
Issues replicated by a different replicator (that is, the
replicator identifier for those issues differs from the rid configuration parameter);
Issues not replicated by any replicator and unchanged since the start date.
Each element fetched by the returned cursor must belong to your
subclass of the dt_interface.defect_tracker_issue class (see section 7.2).
changed_entities(self) This method is called at the start of each replication cycle to
determine what work there is to do. The method poll_start is called just before this.
It must return a tuple of three elements:
A cursor (see section 7.6) that fetches the defect tracking issues that require replication.
Each element fetched by the returned cursor must belong to your
subclass of the dt_interface.defect_tracker_issue class (see section 7.2).
Include in the cursor:
Issues replicated by this replicator (that is, the
replicator identifier for those issues matches the rid configuration parameter);
Issues not replicated by any replicator (that is, the replicator identifier for those issues is blank). The replicator considers these issues as candidates for replication.
Omit from the cursor:
Issues replicated by a different replicator (that is, the
replicator identifier for those issues differs from the rid configuration parameter).
Issues known to be up to date with Perforce; either because they are unchanged since they were last replicated, or because they have only been changed by the replicator (see section 4.6 and section 4.7).
The empty list [ ]. (This is for
symmetry with the Perforce interface, which returns a list of
changelists. Since changelists are not editable in the defect
tracker, there's nothing that can be returned here, hence the empty
list.)
A marker. This must be some token that identifies what has
been done on this poll. At the end of the replication cycle it is
passed to mark_changes_done.
Example. The TeamTrack integration used the record number of the last record in the
TS_CHANGEStable that the replicator looked at as the marker indicating what it's done. See the design [GDR 2000-09-04, 3.5].
This method must not record that the issues it returns have been considered for replication or replicated. The replicator can encounter an error during the course of replication that prevents it from making any progress (Perforce can go down, the defect tracker can go down, the replicator can crash). When the system comes back up, the replicator must re-consider these issues and possibly replicate them again. This helps keep the databases consistent (requirement 1) and is consistent with the design principle that the replicator must have no internal state (see section 4.5).
Recording that issues have been replicated must be left for the end
of each replication cycle, when the marker (the third item in the tuple)
is passed to mark_changes_done.
init(self) This method is called each time the replicator starts.
The method must initialize the defect tracking database so that it is ready to start replication. The tables and fields in your schema extensions (see section 4) must be added if they are not yet present.
issue(self, issue_id) Return the defect tracking issue identified by the issue_id argument, or None if there is no such
issue. The returned issue (if any) must belong to your subclass of the
dt_interface.defect_tracker_issue class (see section 7.2).
The issue_id argument is a string
identifying the issue (see section 7.2.1).
mark_changes_done(self, marker) This method is called at the end of each replication cycle, when all issues have been replicated.
The marker argument is the third item in
the tuple returned by the changed_entities method at the start of the
replication cycle.
This method must now record that it has considered all changes up to the start of this replication cycle and replicated them successfully, so that at the next replication cycle it can ignore these changes and consider a new set of changes (see section 4.6).
new_issue(self, dict, jobname) (The new_issue method belongs to the migrate_issues and new_issues features.)
Create a new issue in the defect tracker and set it up for
replication (this is called both during migration from Perforce jobs,
and when a new job has been created in Perforce). The dict argument is a dictionary mapping defect
tracker field name to a value for that field (the values have been
translated from Perforce), and the jobname
argument is the name of the corresponding job in Perforce.
You should do your best to supply default values for required fields
if they are not present in dict, and you
should try to avoid defect tracker workflow constraints (such as
insisting that an issue start out in a particular state). If all else
fails, raise an error.
Return the newly-created issue as an object belonging to the defect_tracker_issue
class.
The newly-created issue should respond in future as if its setup_for_replication method had been called
with jobspec as the argument. It is up to
you whether to call that method or implement the effect in some other
way.
This method is optional. You need not provide it if you don't support migration from Perforce.
new_issues_start(self) (The new_issues_start method belongs to
the migrate_issues and new_issues features.)
This method is called by the P4DTI just before it starts migrating jobs from Perforce to the defect tracker.
If you need to take a lock in the defect tracker database, take it
here and release it in new_issues_end.
This method is optional. You need not provide it if you don't support migration from Perforce.
new_issues_end(self) (The new_issues_end method belongs to
the migrate_issues and new_issues features.)
This method is called by the P4DTI just after it finishes migrating jobs from Perforce to the defect tracker.
If you needed to take a lock in the defect tracker database, in new_issues_start, release it here.
This method is optional. You need not provide it if you don't support migration from Perforce.
poll_start(self) This method is called by the P4DTI just before it polls the defect tracker with
the changed_entities method to discover changed
entities.
If you need to take a lock in the defect tracker database, take it
here and release it in poll_end.
This method is optional. You need not provide it.
poll_end(self) This method is called by the P4DTI at the end of each replication cycle. It is called whether or not the replication succeeded.
If you needed to take a lock in the defect tracker database, in poll_start, release it here.
This method is optional. You need not provide it.
replicate_changelist(self, change, client, date, description, status, user) (The replicate_changelist method belongs
to the fixes feature.)
Replicate a changelist to the defect tracker database (see section 4.2).
The arguments specify the changelist; these arguments correspond to a subset of the fields in the changelist relation in the Perforce database (the names of the actual files changed, and their new revision numbers, are not replicated).
changeThe change number (an integer).
clientThe client on which the change was last modified (a string).
dateThe date and time at which the change was last modified. It has been converted by the date translator (see section 7.5.1).
descriptionThe change comment. It has been converted by the text translator (see section 7.5.3).
status "pending" if the changelist is
pending, "submitted" otherwise.
userThe user who last modified the changelist. It has been converted by the user translator (see section 7.5.4).
This method must return 1 if the changelist was new or changed, or 0 if it was unchanged.
supports(self, feature) Return 1 if your integration supports the feature named by the
feature argument (a string); return 0 if you
don't support the feature. See section 3.5
for the list of optional features. If you don't recognize the feature,
return 0.
dt_interface.defect_tracker_issue class A subclass of dt_interface.defect_tracker_issue implements the
replicator's interface to the issues in a defect tracker.
Example. The
dt_bugzilla.pymodule defines a classbugzilla_bug(issues are called "bugs" in Bugzilla).
The replicator needs a unique identifier for each issue in the
defect tracker. This must be a string, so that it can be stored in the
P4DTI-issue-id field in the Perforce jobspec
[GDR
2000-09-13, 4.2]. The replicator gets the identifier from an
issue's id method. Later, it may pass the
identifier to the defect tracker's issue method.
Example. Bugzilla uniquely identifies bugs by their bug number. So in the
dt_bugzillamodule, the issue identifier is the string conversion of the bug number.
The replicator considers an issue to consist of a collection of
named fields, with a value for each field. Instances of the defect_tracker_issue subclass must support at
least the __getitem__ method, so that the replicator
can get the value for a field in an issue using the expression issue["fieldname"].
You may want to implement the whole of the Python dictionary
interface for your own use, but the replicator only uses
__getitem__.
A subclass of dt_interface.defect_tracker_issue must define the
following methods:
__getitem__(self, field) Return the value of the field named by the field argument. Raise KeyError if the issue has no such field.
__str__(self) Return a string describing the issue, suitable for presentation to a user or administrator in a report. Having several lines of the form "field name: value" is fine.
add_filespec(self, filespec) (The add_filespec method belongs to the filespecs feature.)
Add a filespec to the issue (see section 4.4).
The argument is the filespec to add (a string).
add_fix(self, change, client, date, status, user) (The add_fix method belongs to the fixes feature.)
Add a fix to the issue (see section 4.3).
The arguments specify the fix; these arguments correspond to the fields in the fix relation in the Perforce database.
changeThe Perforce change number (an integer).
clientThe Perforce client name from which the fix was made (a string).
dateThe date the fix was made. It has been converted by the date translator (see section 7.5.1).
statusThe effect of the fix. It is the status the job was changed to when the fix was made (or if the fix is to a pending changelist, then this is the status the job is changed to when the changelist is submitted).
The status is also known as the "effect" (for example, in the defect tracker's interface to fixes (see section 9)) because it gives the effect on the job when the fix is submitted.
userThe user who made the fix. It has been converted by the user translator (see section 7.5.4).
corresponding_id(self) If this issue has been replicated, return the name of the Perforce job to which this issue is replicated.
If this issue has not yet been replicated, return the name for the
Perforce job to which this issue is replicated. The returned value must
be legal as the name of a Perforce job. You may want to use the result
of the readable_name method if that is
suitable.
delete(self) (The delete method belongs to the migrate_issues and new_issues features.)
Delete the issue from the defect tracker (or flag the issue so that
it is not returned by the all_issues and changed_entities methods in future, if
deletion is impossible).
This method is only ever called of an issue that has just been
created by the new_issue method, if an error occurred while
setting up the new issue.
filespecs(self) (The filespecs method belongs to the filespecs feature.)
Return a list of the filespecs associated with this issue. Each
item in the list belongs to your subclass of the defect_tracker_filespec class (see section 7.4).
fixes(self) (The fixes method belongs to the fixes feature.)
Return a list of the fixes for this issue. Each item in the list
belongs to your subclass of the defect_tracker_fix class (see section 7.3).
id(self) Return a string that can be used to uniquely identify this issue among all the issues in the defect tracker and to fetch it in future (see section 7.2.1).
readable_name(self) Return a string giving a human-readable name for the issue. This name is only used in logs and e-mail messages.
rid(self) Return the replicator identifier of the replicator that is in charge of replicating this issue, or the empty string if the issue is not being replicated.
setup_for_replication(self, jobname) Set up the issue for replication. That is, record that the issue is replicated by this replicator and record any other information in the database that is needed to replicate this issue.
You must do at least these three steps:
Record that the issue is replicated by this replicator, so
that in the future its rid method returns the correct replicator
identifier (this is the rid parameter in
the configuration passed to the defect tracker class when it was
instantiated).
Record the Perforce server identifier of the Perforce server
it is replicated to (this is the sid
parameter in the configuration passed to the defect tracker class when
it was instantiated).
Record that the issue is replicated to the Perforce job named
by the jobname argument, so that in future
its corresponding_id method returns jobname.
See section 4.1.
update(self, user, changes) Update the issue in the defect tracker's database.
The user argument is the user who made
the change. It has been converted by the user translator (see section 7.5.4).
The changes argument is a dictionary of
the changes that must be applied to the issue. The keys of the
dictionary are the names of the fields that have changed; the values are
the new values for those fields. Each value in the dictionary has been
converted by the appropriate translator. If changes is the empty dictionary, then do
nothing.
If the defect tracker supports transitions in a workflow, then this method should deduce the transition to apply (if any) based on the old and new values for the issue fields.
Example. The TeamTrack integration attempted to find and apply a transition when the
STATEfield changes. It looked at all the available transitions for the issue and selected the transition resulting in the correct new state.
Example. Bugzilla doesn't have transitions as distinguished workflow objects, so there's no need for the Bugzilla integration to deduce one.
This method must check that the proposed change to the issue is legal in the defect tracker. (The changed fields have been converted by their translators, so each is legal individually, but the defect tracker may be more stringent, for example it may require a field not to have a value when the issue is in a particular state.) It must also check that the user has permission to make the proposed change. It's best if you can call a function in the defect tracker's API to apply the defect tracker's own rules (this is likely to be robust and maintainable), but if there's no such function, then you must do your best to emulate the defect tracker's checks.
If the issue can't be updated (for example, because the user doesn't have permission to make the change, or because no workflow transition can be discovered, or because the proposed change is illegal in some way) then this method must raise an error.
Example. The TeamTrack integration called the
TSServer::Transitionmethod in the TeamShare API, which checked the issue for correctness and checked that the user has the correct privilege. All the integration needed to do is raise an error if the function rejected the transition.
Example. Bugzilla has no API, so the Bugzilla integration must emulate Bugzilla's checking. The
dt_bugzilla.pymodule defines three checking methods:restrict_fields,enforce_invariants, andcheck_permissions.
dt_interface.defect_tracker_fix class (The defect_tracker_fix class belongs to
the fixes feature.)
A subclass of dt_interface.defect_tracker_fix implements the
replicator's interface to a fix record in a defect tracker (see section 4.3).
Example. The
dt_bugzilla.pymodule defines a classbugzilla_fix.
A subclass of dt_interface.defect_tracker_fix must define the
following methods:
change(self) Return the change number for the fix, an integer.
delete(self) Delete the fix in the defect tracker so that the change is no longer linked to the issue.
status(self) Return the status of the fix, a string.
update(self, change, client, date, status, user) Update this fix in the defect tracker so that has the given fields. If the fields are unchanged, do nothing.
This method is called when someone makes a new fix between the change and issue of an existing fix (for example, the status used to be "open", but now is "closed"). Since there can be only one fix for a given change and issue, the replicator updates the fix rather than creating a new fix.
The arguments specify the fix; these arguments correspond to the fields in the fix relation in the Perforce database.
changeThe Perforce change number (an integer).
clientThe Perforce client name from which the fix was made (a string).
dateThe date the fix was made. It has been converted by the date translator (see section 7.5.1).
statusThe effect of the fix. It is the status the job was changed to when the fix was made (or if the fix is to a pending changelist, then this is the status the job is changed to when the changelist is submitted).
The status is also known as the "effect" (for example, in the defect tracker's interface to fixes (see section 9)) because it gives the effect on the job when the fix is submitted.
userThe user who made the fix. It has been converted by the user translator (see section 7.5.4).
dt_interface.defect_tracker_filespec class (The defect_tracker_filespec class
belongs to the filespecs feature.)
A subclass of dt_interface.defect_tracker_filespec implements the
replicator's interface to a filespec record in a defect tracker (see section 4.4).
Example. The
dt_bugzilla.pymodule defines a classbugzilla_filespec.
A subclass of dt_interface.defect_tracker_filespec must define the
following methods:
delete(self) Delete the filespec record so that the issue is no longer associated with the filespec.
name(self) Return the filespec, a string.
translator.translator class A subclass of translator.translator
translates values of a particular type between the defect tracker and
Perforce. You should define a translator for each field type in the
defect tracker that you want the P4DTI administrator to be
able to replicate. You must define translators for dates (see section 7.5.1), multi-line text fields (see section 7.5.3), and users (see section 7.5.4). If your defect tracker has any
concept of the state of an issue, then you must define a translator for
states (see section 7.5.2).
Example. The TeamTrack integration defined, in addition to the three required translators, translators for: fields that cross-referenced an auxiliary table like
TS_PROJECTS; elapsed time fields; selection fields; and theSTATEfield.
The translator base class doesn't know anything about Perforce; all it knows is that it is translating between two defect trackers, called 0 and 1. In the P4DTI, defect tracker 1 is always Perforce, but we haven't limited the design of the translator class by requiring that it is.
Each subclass of translator.translator
must define the following methods:
translate_0_to_1(self, value, dt0, dt1, issue0=None, issue1=None) Return value, suitably translated from
defect tracker 0 to defect tracker 1. If translation is not possible,
raise an error.
valueThe value for a field in a defect tracker issue that is to be translated.
dt0 Your defect tracker: an instance of your subclass of dt_interface.defect_tracker.
dt1 Perforce (represented by an instance of a subclass of dt_interface.defect_tracker).
issue0 The issue in your defect tracker from which the value comes,
or None if the value doesn't come from an
issue. An instance of your subclass of dt_interface.defect_tracker_issue.
issue1 The job in Perforce to which the value is going, or None if the value isn't going to a job
(represented by an instance of a subclass of dt_interface.defect_tracker_issue).
This method takes defect trackers as arguments because it may need to query the defect tracker to carry out the translation.
Example. In the TeamTrack integration, the single select translator needed to read the
TS_SELECTIONStable to discover the available selections. To do this it called the private methodread_selectionsindt0.
This method takes issues as arguments because some translators need to know about the whole issue in order to carry out the translation.
Example. In the TeamTrack integration the state translator needed to know the project to which the issue belonged (because different projects may have different states with the same name which correspond to the same Perforce state).
Many translators can ignore the dt0 and
dt1 arguments; most can ignore the issue0 and issue1
arguments.
translate_1_to_0(self, value, dt0, dt1, issue0=None, issue1=None) Return value, suitably translated from
defect tracker 1 to defect tracker 0. If translation is not possible,
raise an error.
valueThe value in a job in Perforce that is to be translated.
Warning. Be careful not to assume that a value in
field in Perforce is valid for that field. Perforce's checks on field
values can be bypassed (for example, by the -f option to the p4
job command, or by editing a job and changing the jobspec to
make the job invalid). So you should do something appropriate with
invalid values, such as raising an error, or substituting a default
value. It's particularly important to be able to do something
sensible with the empty string, which is what you'll get when there's
no value for that field in Perforce.
dt0 Your defect tracker: an instance of your subclass of dt_interface.defect_tracker.
dt1 Perforce (represented by an instance of a subclass of dt_interface.defect_tracker).
issue0 The issue in your defect tracker to which the value is going,
or None if the value isn't going to an
issue. An instance of your subclass of dt_interface.defect_tracker_issue.
issue1 The job in Perforce from which the value comes, or None if the value doesn't come from a job
(represented by an instance of a subclass of dt_interface.defect_tracker_issue).
Warning. Be careful not to assume that the
dictionary representing the job has all fields present. It's possible
that it has only a subset of fields. So don't write issue1['Spong'], write if
issue1.has_key('Spong'): or issue1.get('Spong',
default_value).
You must define a date translator class, a subclass of translator.translator, to translate dates
between your defect tracker and Perforce.
When translating to Perforce:
An empty or null date field must be translated to the empty string.
Any other date must be translated to a string looking like
"2000/12/31 23:59:59" (you can do this by
calling time.strftime with "%Y/%m/%d %H:%M:%S" as the first
argument).
When translating from Perforce:
The empty string must be translated to an empty or null date field.
A string in the format "2000/12/31
23:59:59" specifies the calendar date. (This form is used by
changelists and jobs.)
A string consisting only of digits specifies the number of seconds since 1970-01-01 00:00:00 UTC. (This form is used by fixes.)
Timezones. When Perforce creates a timestamp for a
changelist or for a field in job with a preset of $now, it uses local time on the Perforce server.
For other date fields in jobs, Perforce just stores the date the user
entered, without conversion. Your date translator must make sure that
its translations in the two directions are inverses of each other. The
simplest way to do this is to follow the same principle as the Perforce
server: just treat the date as you get it, without conversion.
Example. TeamTrack specifies all dates as seconds since 1970-01-01 00:00:00, so the TeamTrack integration used
time.strftimeto convert from TeamTrack to Perforce, and eithertime.mktimeor simplyintto convert from Perforce to TeamTrack.
If your defect tracker has a concept of states for issues, then you
must define a state translator class, a subclass of translator.translator.
The state field in Perforce should be a "select" field (see section 8.4) so the values for this field should be legal selections in Perforce. This means no whitespace, hashes, double quotes, semicolons or slashes. Since the defect tracker probably allows these character to appear in state names, you must convert them somehow.
We have provided a translator to do this conversion: it is the
keyword_translator class in the translator.py module.
You shouldn't just use the keyword translator as your state translator, since all it does is to convert strings. You should develop a translator that checks that applies the keyword translator, checks that the converted state is legal and raises an error if it is not.
You must define a text translator class, a subclass of translator.translator, to translate multi-line
text fields between your defect tracker and Perforce.
This translator must translate line endings (if needed). Perforce
uses newline ("\n") as the line ending;
values always end in a newline (unless the field is empty); values never
end in more than one newline.
Example. TeamTrack uses a carriage return plus a newline (
\r\n) as its line ending, and there need not be a final newline.
Example. The MySQL database interface converts newlines if necessary, so the Bugzilla integration uses
translator.translator(a translator which does nothing) for its text translator.
You must define a user translator class, a subclass of translator.user_translator, to translate users
between your defect tracker and Perforce.
It is important not to assume that userids are the same in Perforce and the defect tracker, because an organization may have different policies for assigning userids in the two systems, or there may be legacy users from a previous policy. The TeamTrack and Bugzilla integrations translate between users based on their e-mail addresses. Your integration should do the same if possible and appropriate.
When translating from the defect tracker to Perforce:
Map the defect tracker user to a Perforce user with the same e-mail address, if there is one.
Otherwise, map the defect tracker user to the Perforce user with the same userid, if there is one.
Otherwise, return the defect tracker userid unchanged (assuming it is valid syntactically as a Perforce userid; if it isn't, apply the keyword translator (see section 7.5.2) to it).
When translating from Perforce to the defect tracker:
Map the Perforce user to a defect tracker user with the same e-mail address, if there is one.
Otherwise, map the Perforce user to the defect tracker user with the same userid, if there is one.
Otherwise, if translating the user in a changelist or fix, map
the Perforce user to some dummy defect tracker user (see section 4.8). You can tell that you're translating a
changelist or fix rather than an issue because the issue0 argument to the translate_1_to_0 method is None.
Otherwise, you're translating a user field in an issue and you can't find a match either by e-mail address or by name. Raise an error.
Each subclass of translator.user_translator must define the
following method:
unmatched_users(self) This method should examine all the users in the defect tracker and Perforce and return a report on the users in each system that have no corresponding userid in the other.
It must return a tuple. The first four elements of the tuple must be as follows:
A dictionary of users in the defect tracker that have no corresponding userid in Perforce. The keys of the dictionary are strings naming the defect tracker userids; the values of the dictionary are the e-mail addresses of the defect tracker users.
A dictionary of users in Perforce that have no corresponding userid in the defect tracker. The keys of the dictionary are the Perforce userids; the values of the dictionary are the e-mail addresses of the Perforce users.
A comment (a string or message) about the users in the first dictionary explaining how they are treated by this user translator.
Example. The Bugzilla integration says, "A user field containing one of these users will be translated to the user's e-mail address in the corresponding Perforce job field."
A comment (a string or message) about the users in the second dictionary explaining how they are treated by this user translator.
Example. The Bugzilla integration says "It will not be possible to use Perforce to assign bugs to these users. Changes to jobs made by these users will be ascribed in Bugzilla to the replicator user."
Optionally, the returned tuple may have four additional elements:
A dictionary of users in the defect tracker that have duplicate e-mail addresses, and which therefore may have been matched to the wrong user in Perforce. The keys of the dictionary are strings naming the defect tracker userids; the values of the dictionary are the e-mail addresses of the defect tracker users.
A dictionary of users in Perforce that have duplicate e-mail addresses, and which therefore may have been matched to the wrong user in the defect tracker. The keys of the dictionary are the Perforce userids; the values of the dictionary are the e-mail addresses of the Perforce users.
A comment (a string or message) about the defect tracker users
with duplicate e-mail addresses, explaining what the problem is. If
there are no such users, then you may specify None here.
Example. The Bugzilla integration says, "These Bugzilla users have duplicate e-mail addresses (when converted to lower case). They may have been matched with the wrong Perforce user."
A comment (a string or message) about the Perforce users with
duplicate e-mail addresses, explaining what the problem is. If there
are no such users, then you may specify None here.
Example. The Bugzilla integration says, "These Perforce users have duplicate e-mail addresses. They may have been matched with the wrong Bugzilla user."
This method is called each time the replicator is started. The results are used to compose an e-mail to the P4DTI administrator reporting on unmatched users.
The all_issues and changed_entities methods return cursors. A
cursor is a representation of the result set of a query into a database.
It has the following method:
fetchone(self) Return the next item in the result set, or None if there are no more items.
This section describes how to configure the P4DTI to work with your extension. To understand how the configuration works, see [GDR 2000-09-13, 5].
You must write a configuration generator for your defect tracker.
This must be a module called config_defect_tracker.py, where
defect_tracker is the name you chose for your defect tracker (see
section 3), converted to lower case.
It must provide the following function:
configuration(config) The config argument is a module whose
members are the configuration parameters specified by the P4DTI administrator
in config.py.
It must check all the user configuration parameters that are specific to your defect tracker.
It must return a revised configuration module, which should include
all the configuration parameters in the config argument, plus the configuration parameters
required by your defect tracker module, by the replicator (see section 8.3), and by the Perforce interface (see
section 8.2). It's OK to modify the
configuration module that you were passed and return that.
The revised configuration module must include the following
parameter for the Perforce interface. (This is in addition to the
parameters p4_client_executable, p4_password, p4_port, and p4_user which came from the user
configuration.)
logger This is a logger object (see section 5.3)
to which log messages are written. It must log to log_file if that is specified, to standard
output, and to any appropriate system logging facility. It must respect
the log_level.
The revised configuration module must include the following
parameters for the replicator. (These are in addition to the administrator_address, p4_user, poll_period, replicate_p, replicator_address, rid, and smtp_server parameters which came from the
user configuration.)
date_translatorA date translator instance (see section 7.5.1).
field_mapA description of how fields map from the defect tracker to Perforce and back again. It is a list of tuples, one for each field to be replicated. Each tuple has three elements:
The name of the field in the defect tracker.
The name of the field in Perforce.
A translator instance (see section 7.5) that can be used to translate between values in the two fields.
The field map must match the defect tracker database and the jobspec
configuration parameter.
job_owner_fieldThe name of the field in the Perforce jobspec which contains the owner of the job.
Example. In the TeamTrack integration, this was
"Owner". In the Bugzilla integration, this is"Assigned_To".
job_status_fieldThe name of the field in the Perforce jobspec which contains the status of the job.
Example. In the TeamTrack integration, this was
"State". In the Bugzilla integration, this is"Status".
jobspec The Perforce jobspec which the replicator is going to use, or None if the Perforce jobspec is left
unchanged.
The jobspec must be in the format described in section 8.4 and must match the field_map
configuration parameter.
loggerThis must be the same as the logger object for the Perforce interface.
prepare_issue_advanced(config, dt, p4, issue, job) (The prepare_issue_advanced function
belongs to the new_issues feature.)
A function to complete the transformation of a new job in Perforce to an issue in the defect tracker. The function takes 5 arguments:
configA Python module containing the replicator configuration.
dt Your defect tracker: an instance of your subclass of dt_interface.defect_tracker.
p4 Perforce (represented by an instance of a subclass of dt_interface.defect_tracker).
issue The partly-constructed issue, in the form of a Python
dictionary mapping field name (string) to field value. (The values in
the dictionary are the result of applying the translators in the field_map to
the fields in the job.)
jobThe newly-created job, in the form of a Python dictionary mapping field name (string) to field value (string).
The function must modify issue so that
it is a valid issue for creation in the defect tracker, by supplying
values for the defect tracker's required fields. The function should do
so by modifying issue as far as possible
automatically, then calling the function given by the prepare_issue configuration parameter, passing
the modified issue and job arguments.
You need not supply this function in the replicator configuration if you don't support replication of jobs from Perforce to the defect tracker.
text_translatorA text translator instance (see section 7.5.3).
translate_jobspec_advanced(config, dt, p4, job) (The translate_jobspec_advanced function
belongs to the migrate_issues
feature.)
A function to translate a job from the old jobspec (before
migration) to the new jobspec (after migration, suitable for
replication). The function takes 4 arguments; the config, dt and p4 arguments are the same as for prepare_issue_advanced. The job argument is the old job, in the form of a
dictionary mapping field name to field value. The new job must be
returned in the same form (it's OK to update the argument and return
that).
You need not supply this function in the replicator configuration if you don't support migration of jobs from Perforce to the defect tracker.
user_translatorA user translator instance (see section 7.5.4).
The configuration generator must build a Perforce jobspec that
matches the field_map configuration parameter that it
generates. This must be communicated to the replicator as the jobspec
configuration parameter.
The jobspec must be represented by a tuple with two elements:
An introductory comment, in the form of a string starting with
"#".
A list of field definitions. Each field definition must be a tuple of eight elements. See [Perforce 2001-06-18b, 5] for the full details of job specifications.
A unique integer identifier by which this field is indexed. Must be between 101 and 199.
The name of the field as it appears in the job form.
The field datatype ("word", "text", "line",
"select", or "date").
The recommended size of the field's text box as displayed in P4Win.
The field disposition:
"optional": field can take any
value or can be deleted.
"default": a default value is
provided, but it can be changed or erased.
"required": a default is given;
it can be changed but the field can't be left empty.
"once": read-only; the field is
set once to a default value and is never changed.
"always": read-only; the field
value is reset to the default value when the job is saved.
The default value for the field, if any, or None if there is no default value (this is
called "Preset" in the Perforce jobspec).
The legal values for the field, if type is "select", or None
for other types. Join the values into a string, separating them with
slashes. For example, "open/closed/suspended".
A string describing the field, or None if you have nothing to say about the field.
Don't start it with a "#".
Perforce requires that five fields be present in the jobspec:
The jobname (101, "Job", "word", 32,
"required", None, None, "The job name."). This must not be
replicated.
The status of the job (field 102). This should be replicated
from the defect tracker. It should have type "select". Its values should include all the
statuses for issues in the defect tracker, converted using the state
translator (see section 7.5.2).
The owner of the job (field 103). This should be replicated
from the defect tracker. It should have type "word".
The date the job was last modified (104,
"Date", "date", 20, "always", "$now", None, "The date this job was
last modified."). This must not be replicated.
The title (field 105). This should be replicated from the
defect tracker. It should have type "line" or "text".
Example. In the Bugzilla integration, Perforce's five required fields are specified in the jobspec like this:
(101, "Job", "word", 32, "required", None, None, "The job name."), (102, "Status", "select", 11, "required", "unconfirmed", "unconfirmed/bugzilla_new/assigned/reopened/closed/verified/bugzilla_closed", " The bug's status."), (103, "Assigned_To", "word", 255, "required", "$user", None, "User to which the bug is assigned."), (104, "Date", "date", 20, "always", "$now", None, "The date this job was last modified."), (105, "Summary", "text", 0, "required", "$blank", None, "The bug's summary"),
The replicator requires that four fields be present [GDR 2000-09-13, 4]. These should appear in the jobspec as follows:
(191, "P4DTI-filespecs", "text", 0, "optional", None, None, "Associated filespecs."), (192, "P4DTI-rid", "word", 32, "required", "None", None, "P4DTI replicator identifier. Do not edit!"), (193, "P4DTI-issue-id", "word", 32, "required", "None", None, "Bugzilla issue database identifier. Do not edit!"), (194, "P4DTI-user", "word", 32, "always", "$user", None, "Last user to edit this job. You can't edit this!"),
These fields have high numbers so that they appear at the bottom of the jobspec where people don't have to look at them.
The remainder of the jobspec should be filled in with the fields
that the P4DTI
administrator has specified for replication in the replicated_fields configuration parameter.
Make sure that the values for "select" fields are legal in Perforce (see
section 7.5.2).
For more information about jobspecs, see Chapter 5, "Customizing Perforce: Job Specifications", in the Perforce System Administrator's Guide [Perforce 2001-06-18b, 5].
If your defect tracker module (see section
7) requires the P4DTI administrator to specify any configuration
parameters (such as the name of the host on which the defect tracker
runs, or the user to connect to the database as), then you must adapt
the config.py module, as follows.
Add a new # dt_name =
"Defect_Tracker" line near the start of section 2, to
indicate that your defect tracker integration is available.
Add a new subsection to section 3, starting elif dt_name == "Defect_Tracker":. This
should contain default values for the configuration parameters
required only by your integration.
Add a history entry to Appendix B explaining what you've done.
Warning: The configuration methods in this section are not supported by Perforce or TeamShare.
This section describes techniques you can use if you want to adapt a supported integration to do something that's not supported. Here are some of the things that are possible by making your own configuration.
Here's are the steps you need to follow to make your own configuration:
Choose a name for your configuration: my_configuration, say.
Edit config.py, adding the
line
configure_name='my_configuration' Make a new module configure_my_configuration.py.
Make your new module into a configuration generator (see section 8.1). See below for some examples.
The best approach to making a configuration generator is to use an existing one and modify its output. That way, you benefit from improvements and corrections to the configuration generator in future releases of the P4DTI.
Suppose that you are using the Bugzilla integration, but you have tools that work on Perforce jobs that have assumptions about the names of fields in the jobspec. You want the fields in the Perforce jobspec to be called State, User and Description, not Status, Assigned_To and Summary. If the Description field is replicated from Bugzilla, you want it to be called Long_Description in Perforce.
The following configuration generator achives the above:
import configure_bugzilla
import re
import string
convert = {
'Status': 'State',
'Assigned_To': 'User',
'Summary': 'Description',
'Description': 'Long_Description',
}
def configuration(config):
config = configure_bugzilla.configuration(config)
# Convert field names in the jobspec.
f = config.jobspec[1]
for i in range(len(f)):
if convert.has_key(f[i][1]):
f[i] = (f[i][0], convert[f[i][1]]) + f[i][2:]
# Convert Perforce field names in field_map to match the jobspec.
f = config.field_map
for i in range(len(f_map)):
if convert.has_key(f_map[i][1]):
f[i] = (f[i][0], convert[f[i][1]], f[i][2])
return config
Suppose that you want to use the Bugzilla integration, but you have many existing tools and documents that refer to your current Perforce jobspec, so don't want the P4DTI to change your Perforce jobspec.
First, you must add the fields required by the P4DTI [GDR 2000-09-13, 4] to your Perforce jobspec by hand. The following configuration generator achieves this:
import configure_bugzilla
import message
import translator
product = "My configuration"
error = "My configuration error."
catalog = {
1: (message.ERR, "Unknown Bugzilla status '%s'."),
2: (message.ERR, "Unknown Perforce status '%s'."),
}
factory = message.catalog_factory(catalog, product)
# A map from state in Bugzilla to status in Perforce.
state_pairs = [
('NEW', 'new'),
('ASSIGNED', 'open'),
('RESOLVED', 'resolved'),
('CLOSED', 'closed'),
] # No support for UNCONFIRMED, REOPENED, or VERIFIED.
class my_state_translator(translator.translator):
def translate_0_to_1(self, value, dt0, dt1, issue0 = None, issue1 = None):
assert isinstance(value, types.StringType)
for (t,p) in state_pairs:
if value == t:
return p
raise error, factory.new(1, value)
def translate_1_to_0(self, value, dt0, dt1, issue0 = None, issue1 = None):
assert isinstance(value, types.StringType)
for (t,p) in state_pairs:
if value == p:
return t
raise error, factory.new(2, value)
def configuration(config):
config = configure_bugzilla.configuration(config)
# Tell the replicator not to update the jobspec.
config.jobspec = None
# Make a field_map that works with my existing jobspec.
config.field_map = [
('bug_status, 'Status', my_state_translator()),
('assigned_to'', 'User', config.user_translator),
('summary', 'Description', translator.translator()),
('longdesc', 'User_Impact', config.text_translator),
]
return config
Note the use of coding conventions in this example: message catalogs (see section 5.2) and raising exceptions when a value can't be translated (see section 5.4).
Warning. If you leave your Perforce jobspec unchanged, you
must check that it is compatible with the P4DTI. The reason for this is that the
replicator uses p4 -G job -o jobname
to get a job from Perforce; this command applies more stringent checking
than p4 job -o jobname.
Check that the "Presets" for each select field is valid for that field (that is, it appears as one of the "Values" for that field).
Some organizations set up a jobspec with a field like this:
Fields: 120 Severity select 20 required
Values: Severity critical/essential/optional
Presets: Severity setme
Their intention is that since "setme" is not a legal value for the Severity field, the person submitting the job must give it a value; they can't just ignore it and leave it with the default value.
However, this won't work with the P4DTI, because the command p4 -G job -o won't even give you a blank job
form; instead it gives you an error message.
To build the P4DTI, follow the release build procedure [GDR
2000-10-17]. This procedure uses automated support from the build.py tool; this is documented in [GDR 2001-07-13].
You may adapt these three documents so that your new integration built by the same procedure as the other integrations in the P4DTI.
To test the P4DTI, follow the release test procedure [RB
2001-03-21]. This uses the sample data and automated tests in the
test/ directory of the integration kit. See
[GDR 2001-07-02] for
the test design.
You may adapt the existing tests so that they test your integration.
The defect tracker should display, for each issue that is
replicated, a description of the Perforce server to which the issue is
replicated. Use the configuration parameter p4_server_description which you should have
stored in a table in the defect tracker (see section 4.5).
The defect tracker should display the jobname of the job to which
the issue is replicated. The jobname should be a link to the URL given by the job_url configuration parameter, with the
jobname inserted. This configuration parameter is defined in the
Administrator's Guide as being suitable for passing to
sprintf as the format string: it must have
one %s format specified (for which the
jobname is substituted) and it may have any number of doubled percent
signs %% (which must become single percent
signs in the resulting URL) [RB 2000-08-10a,
5.1].
The defect tracker should display on each issue description page a table of fixes for that issue (if there are any). The table should look like the table below.
| Change | Effect | Date | User | Description |
|---|---|---|---|---|
| 5493 | open | 2000-12-05 | GDR | Added replicator method mail_concerning_job for e-mailing people about a job. |
| 5524 | open | 2000-12-06 | GDR | Fixed the replicator's user_email_address method so that it really returns None when there is no such user. |
| 5541 | open | 2000-12-06 | GDR | If the owner of a job and the person who last changed it are the same, include them only once in any e-mail sent by the replicator about that job. |
| 5634 (pending) | closed | 2000-12-07 | GDR | Merging back to master sources. |
Points to note about this table:
Pending changelists are distinguished from submitted changelists. This is important because the effect of a pending changelist does not happen until the changelist is submitted. So in the above table the status of the job is still "open" but it is understood that when changelist 5634 is submitted it becomes "closed".
The user and date are for the change (not for the fix). Knowing when the change was made and by whom is much more important than knowing when the change was linked with the job.
The user is the defect tracker user who corresponds to the Perforce user who made the change.
The change number is a link to the URL given by the changelist_url configuration parameter, with
the change number inserted. This configuration parameter is defined
in the Administrator's Guide as being suitable for
passing to sprintf as the format string:
it must have one %d format specified (for
which the change number is substituted) and it may have any number of
doubled percent signs %% (which must
become single percent signs in the resulting URL) [RB
2000-08-10a, 5.1].
All the fixes for an issue are replicated by the same replicator and from the same Perforce server as the issue itself. So when building this table you only need to select records with the same replicator identifier and Perforce server identifier as the issue.
A single defect tracker may replicate issues to several Perforce servers (see section 4). Each Perforce server has a different changelist URL. So it is important to select the URL for the correct Perforce server (namely the one to which the issue is replicated) when making this table.
When adding material relating to your defect tracker to the manuals,
surround each section with the HTML tags <div
class="defect_tracker"> and </div>. This makes the material for a
particular defect tracker easy to find, extract and check, to meet requirement 32.
You must adapt the Perforce Defect Tracking Integration Administrator's Guide [RB 2000-08-10a] to describe your integration, as described in the list below.
Add a new subsection to section 3, specifying the software and procedural prerequisites for using your defect tracker with the P4DTI.
If your integration requires a new installation procedure, or installs on a new platform, update section 4.
Add your new configuration parameters to section 5.1.
Add a new subsection to section 5, explaining how to configure your defect tracker for the P4DTI.
Add a new item to the list in section 10, explaining how to uninstall your integration and return your defect tracker to its original state.
Add the error messages that your code can produce to section 11.2 (include the product, message identifier and check digit just like the other errors messages in that section).
Add likely error messages from systems with which your code interacts to section 11.3 (for example, errors from the defect tracker, or from your database interface).
Add references to documentation for your defect tracker, and any other supporting materials that you referred to, to appendix A.
Add a history entry to appendix B explaining what you've done.
If you provided an interface from your defect tracker to the Perforce fixes relation (see section 10), then you must adapt the Perforce Defect Tracking Integration User's Guide [RB 2000-08-10b] to describe your integration, as follows:
Add a paragraph to section 10.3 explaining how to access Perforce fixes from the defect tracker.
Defects in the P4DTI Kit include (but aren't limited to):
An essential piece of information can't be found in this manual or in the design documents it refers to.
Inconsistencies between this manual, the design documents it refers to, and the sources they document.
Defects in the P4DTI sources or in the test cases.
Please report any defects you find to Perforce support, so that they can be fixed and the product improved.
Please provide the following information with your defect report:
The release of the P4DTI Kit you are using (look in the readme.txt that came with the P4DTI Kit to
identify the release).
The name and release of the defect tracker you are integrating with.
If you're reporting a defect in documentation:
What you're trying to do.
The information you need.
Where you expected to find it.
Where else you looked for it.
If you're reporting a defect in the code:
What you did immediately prior to the defect's occurrence.
What you think should have happened.
What actually happened.
The Perforce release you are using.
Any source code you've added or modified, including your
config.py file.
A section of the P4DTI log that includes the error that you're reporting and some context around that error.
Copies of any related e-mail messages generated by the P4DTI.
Please send your contributions (fixes, adaptions and extensions) to Perforce support. Please include the following:
A description of your contribution: what it is designed to achieve; which files you've changed; which files you've added.
The release of the P4DTI Kit you have been developing against (look
in the readme.txt that came with the
P4DTI Kit to
identify the release).
The complete P4DTI Kit, including your modifications and
additions. Make a tarball or a ZIP archive of the whole P4DTI Kit
directory. (Please do this even if you've only changed a couple of
files. This allows us to add your contribution to Perforce and use
p4 diff2 to see exactly what changes
you've made.)
What you are prepared for us to do with your contribution. Are you willing for us to make it available for distribution from Perforce or Ravenbrook's web site? Are you willing for us to incorporate it into the P4DTI and maintain and support it? Have you made it available under an open source license?
This section lists significant changes in the specification that a defect tracker has to meet. Changes are upwards compatible (in the sense that a defect tracker module that worked with the previous release of the integration kit will work with the new release) unless stated otherwise.
The all_issues and changed_entities methods of the defect_tracker class (see section 7.1) must now return cursors (see section 7.6), not lists of issues.
The purpose of this change is to allow the replicator to work if there are more issues in the defect tracker than fit into memory, thus fixing job000277.
The release 1.1.1 specification for these two methods (returning lists of issues) is still supported in version 1.4 of the P4DTI, but this support will be removed in later releases.
The all_issues method of the defect_tracker class (see section 7.1) must return all issues replicated
by this replicator, regardless of when they were last modified.
The purpose of this change is to fix job000340.
This is an incompatible change.
The unmatched_users method in the user translator class may return an 8-tuple
instead of a 4-tuple. The extra elements of the tuple allow the
replicator to report duplicate e-mail addresses.
The purpose of this change is to fix job000308.
The defect_tracker class has six new methods:
add_user, new_issue, new_issues_start, new_issues_end, poll_start, and poll_end.
The defect_tracker_issue class has the new
methods: delete.
The purpose of this change is to support migration from Perforce jobs and users (job000022), creation of new issues in Perforce (job000036), and releasing of defect tracker locks (job000306).
These methods are optional: you may omit them if you don't support migration or creation of new issues in Perforce.
The replicator configuration (section
8.3) has two new parameters: prepare_issue_advanced and translate_jobspec_advanced.
The purpose of this change is to support migration from Perforce jobs (job000022).
These methods are optional: you may omit them if you don't support migration of jobs from Perforce to the defect tracker.
The configuration function in the configuration
generator must return the revised configuration module only (not a
tuple of a jobspec description and the revised configuration). The
jobspec description must instead be added to the replicator
configuration as the jobspec parameter, in the format described
in section 8.4.
This is an incompatible change.
The defect_tracker class has the new method supports.
In version 1.4 of the P4DTI, if you don't provide this method, then the
P4DTI will
assume that you support filespecs and
fixes (always), new_issues (if you implement the new_issue, new_issues_start, and new_issues_end methods and provide the prepare_issue_advanced function in the
replicator configuration), migrate_issues (if you support the
new_issues feature and provide the translate_jobspec_advanced function in the
replicator configuration), and new_users (if you implement the add_user method) features. In later
versions, the P4DTI will fail if you don't provide this
method.
The defect_tracker_issue class no longer needs a
replicate_p method (this comes from the user
configuration and the replicator now calls it directly).
The defect_tracker class has the new method add_replicator_user.
| [GDR 2000-05-03] | "Requirements and Use Cases for Perforce/Defect Tracking Integration"; Gareth Rees; Ravenbrook Limited; 2000-05-03. |
| [GDR 2000-05-24] | "Perforce Defect Tracking Integration Project Requirements"; Gareth Rees; Ravenbrook Limited; 2000-05-24. |
| [GDR 2000-05-30] | "Analysis of architectures for defect tracking integration"; Gareth Rees; Ravenbrook Limited; 2000-05-30. |
| [GDR 2000-08-08] | "Python interface to TeamTrack: design"; Gareth Rees; Ravenbrook Limited; 2000-08-08. |
| [GDR 2000-09-04] | "TeamTrack database schema extensions for integration with Perforce"; Gareth Rees; Ravenbrook Limited; 2000-09-04. |
| [GDR 2000-09-13] | "Replicator design"; Gareth Rees; Ravenbrook Limited; 2000-09-13. |
| [GDR 2000-10-17] | "Perforce Defect Tracking Integration Release Build Procedure"; Gareth Rees; Ravenbrook Limited; 2000-10-17. |
| [GDR 2001-07-02] | "Test design"; Gareth Rees; Ravenbrook Limited; 2001-07-02. |
| [GDR 2001-07-13] | "Build automation design"; Gareth Rees; Ravenbrook Limited; 2001-07-13. |
| [GDR 2001-11-14] | "Perforce Defect Tracking Integration Advanced Administrator's Guide"; Gareth Rees; Ravenbrook Limited; 2001-11-14. |
| [ISO 2108] | "ISO 2108: International standard book number (ISBN)"; ISO. |
| [Lutz 1996] | "Programming Python"; Mark Lutz; O'Reilly; 1996-10; ISBN 1-56592-197-6. |
| [NB 2000-11-14a] | "Bugzilla database schema"; Nick Barnes; Ravenbrook Limited; 2000-11-14. |
| [NB 2000-11-14b] | "Bugzilla database schema extensions for integration with Perforce"; Nicholas Barnes; Ravenbrook Limited; 2000-11-14. |
| [NB 2000-11-14c] | "Python interface to Bugzilla: design"; Nicholas Barnes; Ravenbrook Limited; 2000-11-14. |
| [Perforce 2001-06-18a] | "Perforce 2001.1 Command Line User's Guide"; Perforce Software; 2001-06-18; <http://www.perforce.com/perforce/doc.011/manuals/p4guide/>, <ftp://ftp.perforce.com/pub/perforce/r01.1/doc/manuals/p4guide/p4guide.pdf>. |
| [Perforce 2001-06-18b] | "Perforce 2001.1 System Administrator's Guide"; Perforce Software; 2001-06-18; <http://www.perforce.com/perforce/doc.011/manuals/p4sag/>, <ftp://ftp.perforce.com/pub/perforce/r01.1/doc/manuals/p4sag/p4sag.pdf>. |
| [Purcell 2001-02-12] | "PyUnit — a unit testing framework for Python"; Steve Purcell; 2001-02-12. |
| [RB 2000-08-10a] | "Perforce Defect Tracking Integration Administrator's Guide"; Richard Brooksby; Ravenbrook Limited; 2000-08-10. |
| [RB 2000-08-10b] | "Perforce Defect Tracking Integration User's Guide"; Richard Brooksby; Ravenbrook Limited; 2000-08-10. |
| [RB 2000-08-10c] | "Perforce Defect Tracking Integration Architecture"; Richard Brooksby; Ravenbrook Limited; 2000-08-10. |
| [RB 2001-03-07] | "P4DTI Project Contributions Procedure"; Richard Brooksby; Ravenbrook Limited; 2001-03-07. |
| [RB 2001-03-21] | "Release test procedure"; Richard Brooksby; Ravenbrook Limited; 2001-03-21. |
| [van Rossum 2000-10-16] | "Python Tutorial"; Guido van Rossum; 2000-10-16. |
| 2000-10-16 | RB | Created placeholder after meeting with LMB. |
| 2000-12-10 | GDR | Drafted sections 3 and 4. |
| 2000-12-11 | GDR | Drafted sections 2, 5, and 8 and outlined sections 6 and 7. |
| 2000-12-31 | GDR | The table of fixes in section 8 now distinguishes pending from submitted changes. |
| 2001-01-02 | GDR | Added section 7.1 (configuration architecture), figure 1, section 7.5 (customized configuration). Moved text from appendix D of the Administrator's Guide to section 7.5. |
| 2001-02-04 | GDR | Updated definition of defect_tracker.all_issues method. |
| 2001-02-23 | GDR | Added corresponding_id method; revised definition of readable_name method. |
| 2001-03-02 | RB | Transferred copyright to Perforce under their license. |
| 2001-03-13 | GDR | Deleted the recording of conflicts and the need for manual conflict resolution. Conflict resolution is always immediate. |
| 2001-03-20 | GDR | Added overviews of requirements, architecture and design. Included replicator block diagram. Improved links. |
| 2001-03-21 | GDR | Wrote specifications of the defect tracker and translator classes. Described messages, catalogs, logging and errors. Moved logging and errors to new section 5 because it's important; renumbered remaining sections; moved configuration adaption to new section 8.6. |
| 2001-03-22 | GDR | Specified the configuration generator; explained how to make your own configuration (with example code); explained how to adapt the manuals. Gave warning about incompatible jobspecs. Added prerequisites and where to get help. Added section on testing. Added section on code layout. Explained how to report defects and submit contributions. |
| 2001-03-29 | RB | Changed internal and external cross-references to conform with our other documents. Tidied up references to requirements. Removed claims about assigning copyright. Removed section promising to do particular things with contributions. Updated references to Perforce manuals to (latest) release 2000.2. Validated and fixed some broken links. Sorted references section. |
| 2001-05-17 | GDR | Updated signatures of all_issues and changed_entities: these methods return cursors, not lists, to work around job000277. |
| 2001-05-19 | GDR | Added section on making changes. |
| 2001-05-22 | GDR | Noted that a message catalog must not have an entry for message id 0. |
| 2001-06-11 | GDR | Added warning about field values in Perforce. Added section listing significant changes since previous releases. |
| 2001-06-27 | NB | Fix interface to all_issues method to fix job000340. |
| 2001-06-28 | GDR | Added note on timezones. |
| 2001-07-09 | NB | Added job_url configuration parameter. |
| 2001-07-14 | GDR | Added image map to figure 1. Updated references to Perforce manuals from 2000.2 to 2001.1, since we now support the later version. |
| 2001-10-02 | GDR | Extended the unmatched_users method so that the
replicator can report users with duplicate e-mail addresses. |
| 2001-10-23 | GDR | Added migration methods to defect tracker class. |
| 2001-11-01 | NB | Added poll_start and poll_end methods to defect tracker class. |
| 2001-11-05 | GDR | Added prepare_issue_advanced to replicator configuration. |
| 2001-11-20 | GDR | Added translate_jobspec_advanced and jobspec to
replicator configuration. Defined representation of job
specifications. |
| 2001-11-22 | RB | Cross-referenced section on replicate_p to the Perforce Defect Tracking Integration Advanced Administrator's Guide. |
| 2001-12-04 | GDR | Added missing add_filespec method. Added optional features and the supports method. |
| 2002-01-31 | GDR | Include replicate_changelist method in the fixes feature. |
| 2002-02-01 | GDR | Removed replicate_p method from defect_tracker_issue class. |
| 2002-02-03 | GDR | Added missing method delete to the defect_tracker_issue class. |
| 2003-06-02 | NB | Updated for version 2.0: converted TeamTrack examples to
Bugzilla examples, rewrote some TeamTrack references, added the add_replicator_user method. |
This document is copyright © 2001 Perforce Software, Inc. All rights reserved.
Redistribution and use of this document in any form, with or without modification, is permitted provided that redistributions of this document retain the above copyright notice, this condition and the following disclaimer.
This document is provided by the copyright holders and contributors "as is" and any express or implied warranties, including, but not limited to, the implied warranties of merchantability and fitness for a particular purpose are disclaimed. In no event shall the copyright holders and contributors be liable for any direct, indirect, incidental, special, exemplary, or consequential damages (including, but not limited to, procurement of substitute goods or services; loss of use, data, or profits; or business interruption) however caused and on any theory of liability, whether in contract, strict liability, or tort (including negligence or otherwise) arising in any way out of the use of this document, even if advised of the possibility of such damage.
$Id: //guest/robert_cowham/perforce/p4dti-tracker/main/manual/ig/index.html#1 $