SAFARI: CONCEPTION, BIRTH, AND FUTURE DEVELOPMENT OF AN OPEN SOURCE CODE BROWSING SYSTEM
R. B. SLAYMAKER, Jr.
Safari is a web based application
that provides access to hierarchically organized files (programs, images,
documents, or other media) stored in file systems, databases or archiving
systems such as revision control and software configuration management systems.
Multiple versions of any file can be browsed using meta information such
as revision number, revision labels, project membership, change
set numbers, or other methods natural to the structure of the storage system.
Relative links between documents link to the correct revisions of the
target documents as determined by the meta information.
Safari also provides a standard (GNU Make based) framework
for integrating analysis and processing tools and making their output easily
available within the context of the hierarchy the source files are stored
(and thus presented) in.
Safari was conceived as a tool
for publishing automatically extracted documentation for an in-house system,
using a 3rd party documentation extraction tool (Cocoon). The original
(0.0) version is a monolithic perl script that grew from the original design
goals to include source code browsing, syntax highlighting, navigation
of back revisions, a second documentation extractor (pod2html) and activation
of #include files to be links to the appropriate file.
Several key design decisions
in the 0.0 version were validated in practice, others invalidated. When
the burden of maintaining and extending the monolithic script grew too
large, Safari was rewritten and is now headed for a 1.0 version. The 0.5
version is being released under an open source license in conjunction with
this paper, and a demonstration web site is being made available for the
conference.
This paper outlines the past
and near future life cycle of Safari: the design decisions, the current
state, and future directions are all discussed.
Source code browsing systems allow a developers and other interested parties to explore and research bodies of source code. To varying extents, they provide analytical information about the code base, such as indexes of identifiers, meta information such as change logs, labels, file dates and sizes. A few are complete web based SCM (Software Configuration Management) or RCS (Revision Control System) interfaces.
There are many existing systems that provide these features. The Linux Cross Reference project [1] provides browsing and indexing of identifiers for source code and is used by several high profile open source projects and by in-house developers working on proprietary code.
The Perforce Webkeeper [2] provides for simple retrieval of files from a perforce source code repository.
The p4db Depot Browser [3] provides another front end for browsing files held in a perforce browsing system.
Mortice Kern Systems, Inc. provides a web based interface for the Source Integrity Pro [4] software configuration management system. In addition to these, there are probably hundreds of similar open source, closed source, and hand-rolled systems in existence.
[[If you know of any such systems that are distributed free (in either sense), please let me know. Safari's an equal opportunity borrower. Several of the p4db scripts have already been borrowed (with much gratitude).]]
Safari became a source code browser as a means to a different end: we needed to extract source code documentation (using an existing open source tool) and publish it on an intranet. Source code browsing was originally intended to provided a natural navigational interface for this system, but rapidly became the most used feature. As with many open source projects, it grew out of a need to scratch a fairly small itch and is growing to be a very general tool.
The current rewrite of Safari is intended to allow incorporation of many different tools and to be able to interface to a wide variety of file storage and archival systems.
Safari was originally written starting in 1997 to automatically extract and publish documentation from comments in C++ source code kept in a closed source SCM system. The extraction tool in use is Cocoon [5]. The SCM is MKS' Source Integrity [6]. The fact that both of these were pre-existing sytems meant that Safari was initially conceived as cgi-bin to glue together chains of external tools (SI -> Cocoon -> HTTP output).
Over time, feeping creaturism added:
As Safari was extended, it grew beyond it's original mission as a documentation extraction tool and became a tool for researching, reviewing, and discussing code. It turns out that reading code is often easier in a browser than when using typical development environments of SCMs, file system browsers, documentation extractors, HTML browsers, editors, and the like.
The reasons a system such as Safari is more usable than traditional development environments are:
With Safari, checking a file in is publishing it. Checking in is also publishing any documentation to be extracted from it. This turned out to be a very powerful mechanism. We found ourselves storing design documentation in the project. This allowed the design documentation to be automatically associated with the files that it referred to revision by revision, release by release.
In short, we found ourselves using Safari daily as an core technology for software development. It's not the most used or most important system, but it provides significant value to the developers. We extended it several times to incorporate new features, bloating the original script beyond the point of the maintainer's sanity (which may explain a few things about this paper). Eventually it became clear that there was an ecological niche in the broader internet community that a generalized, open source, modular Safari-like system could fill, even given the number of other similar systems available.
In the spring of 1998, I began to rewrite Safari in a more modular fashion while attempting to preserve the aspects that made Safari useful. Another goal was to allow for for easy integration of existing tools without requiring extensive programming knowledge. Perl's very good for controlling external programs, but there are many people with little or no Perl expertise out there.
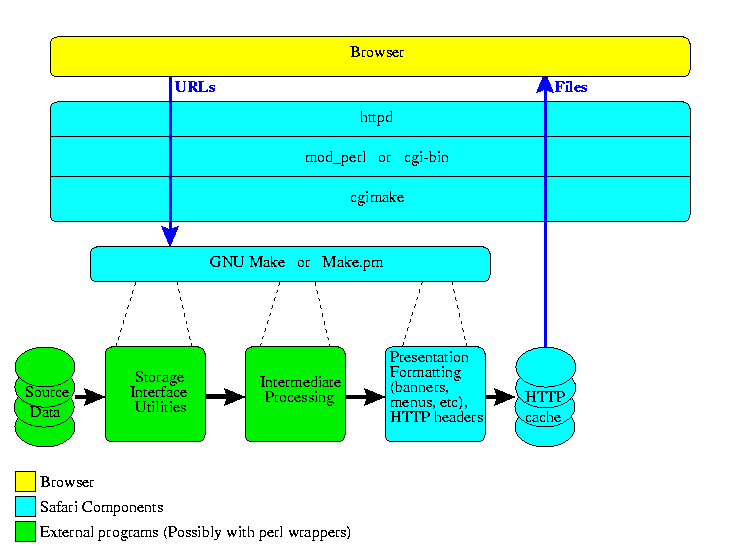
Here's the general structure of a Safari instance:
A fully functional Safari system is built with a web server, a cgi-bin (or preferably mod_perl) script cgimake, a make program, preferably GNU Make or Make.pm, a script to convert source materials into HTTP documents, and any external programs needed to fetch files and meta data from the data store and process it in to web-ready form. These tools are the key element of Safari: they are your existing tools, not special purpose Safari tools.
Several key factors that made the original single-script version of safari useful:
Adding the goals of modularity and extensibility have rounded out Safari and made it a general purpose tool, with possible applications beyond source code browsing.
The key user interface decision that made Safari usable was basing the navigation on the hierarchical file structure present in the source code archives. This structure is already known by existing developers, and basing Safari's navigation system on it also provides a tool for learning and exploration by those who need to become familiar with it. Documentation and other analytical tools should be reachable by browsing to a file or directory, then following a link to the desired output.
The disadvantage of this approach is that popular web browsers make mediocre hierarchy browsers. Javascript, Java, and custom browsers all provide possible avenues of approach for more friendly user interfaces. Safari takes a lowest common denominator approach with low graphics intensity to make it more generally usable. The emphasis is on features, not flash (for now). That being said, a very nice tree oriented GUI would be a fantastic addition.
Alternate browsing structures can easily be provided by adding reports or pages to Safari. These pages can be built automatically by an indexing tool (pod2html does this, for example), or manually. An example of the manual technique is a web page that describes each main active project and provides links to 'interesting' places in it. Interesting places might be the project root, design documents (standalone and automatically extracted), output of analysis tools, key routines, structure definitions, or files within the project, and external resources such as mailing lists, news groups, or other web sites.
A search engine or permuted index generator can provide master 'random access' to the file tree. This is one of the most important features that Safari lacks support for at this time, and is the feature that the Linux Cross Reference Project was built for.
The URL serves as the basic API that ties the user, the browser, and the Safari scripts together. Users often type them in manually instead of browsing to a location, so the URL should be easy to construct manually. In effect, it's a low-level alternate user interface. Browsers base relative link calculations on URLs, so placing contextual information to the left of the destination document's path (as opposed to putting it in a '?' query specification) allows relative links between documents to lead to sensible destinations. And simple, consistent URL design makes scripting the back end much easier.
The URL design must support the hierarchical structure of the underlying archival system, must incorporate a revision identifier and also specification of which analysis or extraction tool's output is being browsed. The typical Safari URL looks like:
http://a.b.com/checkers/_head/pretty/code/inc/checkers.h | | | | | +----------------------+-----+------+------------------+ | Project identity | Rev |Filter| File spec |where:
Safari uses the query string portion of the URL (the part after a '?') to provide transient information. This transient information is information that should not affect the revision or current filter settings, and thus should not affect the document's position in the overall heirarchy.
Here are some examples of Safari URLs. Sample pages generated by these are included in the appendix.
http://localhost/safaridev/perforce/_head/Default/ Leads to a list of files in the top level of Perforce Inc.'s public source code archive. http://localhost/safaridev/perforce/_head/Default/public/index.html Displays the head revision of the index.html extracted from that archive. http://localhost/safaridev/perforce/_head/pretty/public/index.html Displays the same page as syntax highlighted source code http://localhost/safaridev/perforce/_head/pretty/public/index.html?filter=wc Displays the output of the 'wc' command when run on index.html http://localhost/safaridev/perforce/_head/pretty/public/index.html?rev=_head&filter=filelog Displays the complete history of the file index.html. http://www.slaysys.com/safaridev/perforce/@6/Default/public/index.html Diplays the versins of index.html associated with change set number 6.
In essence, each combination of project and revision label or change number specifies a consistent set of files that correspond to each other. The filter determines how the source file should be processed before viewing, and the file spec leads to the file itself.
Some filters generate different namespaces than the underlying archive structure. This makes linking into and out of that filter a little tricky, but relative links between files within a filter's namespace work fine.
It's important to note that links between documents (both hard coded and those automatically marked up by Safari) should be relative links, for two reasons:
This is not always possible given the fact that third party tools are not always prepared to generate relative links. Workarounds do exist for some cases.
A key element in the adoption of Safari was minimal administration. Safari was born out of a need to publish sets of extracted source code documentation on the web, combined with the extreme distaste several of us had for manually generating and publishing docsets.
Safari makes extensive use of file time stamps and meta information from the underlying storage system to determine when to check out a new file or (re)generate output derived from the source files. This can be done on a timed basis (to avoid having to evaluate things every HTTP request), or it can be done on every HTTP request.
In the original script, I found myself using and debugging a lot of dependency rules. This inspired the use of GNU Make as the tool to tie the cgi-bin (or mod_perl) script to the underlying tools.
GNU Make provides several important features for Safari:
GNU Make also poses a few challenges:
Improvements that address the first two of these are now on the TODO list for the GNU Make developers. Workarounds exist for all of these, but improvements should be made that remove them.
A few other key notes about the design and implementation:
Safari's first open source release (0.50) has been developed to coincide with yapc (Yet Another Perl Conference) in June of 1999. The 0.50 release has a full basic feature set, with a lot of room to grow. A demonstration site URL should be available shortly before and for a while after the conference.
Safari's source is all browse-able on the web in the perforce public depot and will be distributed via CPAN in tarball form.
Mailing lists exist for Safari announcements and developer discussions. More details are available on the Safari web site. Please join and contribute.
Safari has a lot of room to grow. It is designed to be an open-ended project. Areas of significant development are:
Please join and contribute!!
Several example pages are given in the order you would browse them in.
| Location: http://localhost/safaridev/perforce/_head/Default/ |
|---|
| The list of depots available at public.perforce.com:1666 |
| perforce/ (Default filter) | ||||||||||
|
PROJECT top up changes labels rebuild |
|
|||||||||
| This page generated by Safari at Wed Jun 16 15:08:39 1999 | ||||||||||
| Location: http://localhost/safaridev/perforce/_head/Default/public/ |
|---|
| The list of depots files available in the public depot ( //public/* ) at public.perforce.com:1666, and their revision levels and last change number, as of the head revision. |
| perforce/public/ (Default filter) | |||||||||||||||||||||||||||||||
|
PROJECT top up changes labels rebuild |
|
||||||||||||||||||||||||||||||
| This page generated by Safari at Wed Jun 16 15:42:46 1999 | |||||||||||||||||||||||||||||||
| Location: http://localhost/safaridev/perforce/_head/Default/public/index.html |
|---|
| The head revision of //public/index.html from public.perforce.com:1666 |
| perforce/public/index.html (HTML filter) | |||||||
|
PROJECT top up changes labels rebuild FILTERS Default POD pretty plain HTML TOOLS gcclint wc filelog |
Welcome to the Perforce Public Depot
[...lots of good information snipped for brevity...]
|
||||||
| This page generated by Safari at Fri Jun 18 02:24:59 1999 | |||||||
| Location: http://localhost/safaridev/perforce/_head/pretty/public/index.html |
|---|
| The syntax highlighted source code for the head revision of //public/index.html from public.perforce.com:1666 |
| perforce/public/index.html (pretty filter) | |
|
PROJECT top up changes labels rebuild FILTERS Default POD pretty plain HTML TOOLS gcclint wc filelog |
1 <HTML> 2 3 <HEAD> 4 5 <TITLE> 6 Perforce Public Depot 7 </TITLE> 8 9 </HEAD> 10 11 <BODY BGCOLOR="#FFFFFF"> 12 <CENTER> 13 <P> 14 <A NAME="toc"></A> 15 <A HREF="http://www.perforce.com"> 16 <IMG SRC="http://www.perforce.com/images/logo.gif" alt="Perforce" border=0></A> 17 <H1> 18 Welcome to the Perforce Public Depot 19 </H1> 20 <P> [...more lines, snipped for brevity...] |
| This page generated by Safari at Fri Jun 18 02:25:38 1999 | |
| Location: http://localhost/safaridev/perforce/_head/pretty/public/index.html?filter=wc |
|---|
| Output of the 'wc' command applied to the file //public/index.html |
| perforce/public/index.html (wc filter) | |
|
PROJECT top up changes labels rebuild FILTERS Default POD pretty plain HTML TOOLS gcclint wc filelog |
453 lines, 1257 words, 12271 bytes in _head/public/index.html |
| This page generated by Safari at Fri Jun 18 02:27:13 1999 | |
| Location: http://localhost/safaridev/perforce/_head/pretty/public/index.html?rev=_head&filter=filelog |
|---|
| The complete revision history of the file //public/index.html |
| perforce/public/index.html (filelog filter) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
PROJECT top up changes labels rebuild FILTERS Default POD pretty plain HTML TOOLS gcclint wc filelog |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| This page generated by Safari at Fri Jun 18 02:27:54 1999 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Location: http://www.slaysys.com/safaridev/perforce/@6/Default/public/index.html |
|---|
| The file index.html as of change number 6. |
| perforce/public/index.html (HTML filter) | |
|
PROJECT top up changes labels rebuild FILTERS Default POD pretty plain HTML TOOLS gcclint wc filelog |
Testing...This is a test.This should be the Perforce home page. |
| This page generated by Safari at Fri Jun 18 04:59:03 1999 | |
[1] The Linux Cross Reference System ( http://lxr.linux.no/ ).
[2] The Perforce WebKeeper ( http://www.perforce.com/perforce/webkeeper.html ).
[3] The p4db Perforce Depot Browser ( http://public.perforce.com/cgi-bin/p4db/dtb.cgi?FSPC=public/perforce/utils/p4db ).
[4] Mortice Kern Systems' Source Integrity Pro Software Configuration Management System ( http://www.mks.com/solution/si/pro/ ).
[5] The Cocoon Utilities, Version 3.2, Jeffrey Kotula ( http://www.stratasys.com/software/cocoon/ ).
[6] Mortice Kern Systems' Source Integrity ( http://www.mks.com/solution/si/ ).